canal源码解析系列(7):driver模块
-
系列文章索引:
driver,顾名思义为驱动。熟悉jdbc编程的同学都知道,当项目中需要操作数据库(oracle、sqlserver、mysql等)时,都需要在项目中引入对应的数据库的驱动。以mysql为例,我们需要引入的是mysql-connector-java这个jar包,通过这个驱动包来与数据库进行通信。
那么为什么canal不使用mysql官方提供的驱动包,而要自己编写一个driver模块?原因在于mysql-connector-java驱动包只是实现了JDBC规范,方便我们在程序中对数据库中的数据进行增删改查。
对于获取并解析binlog日志这样的场景,mysql-connector-java并没有提供这样的功能。因此,canal编写了自己的driver模块,提供了基本的增删改查功能,并提供了直接获取原始binlog字节流的功能,其他模块在这个模块的基础上对binlog字节进行解析,parser模块底层实际上就是通过driver模块来与数据库建立连接的。
driver模块目录结构如下所示:
最核心的3个类分别是:-
MysqlConnector:表示一个数据库连接,作用类似于java.sql.Connection
-
MysqlQueryExecutor:查询执行器,作用类似于PrepareStatement.executeQuery()
-
MysqlUpdateExecutor:更新执行器,作用类似于PrepareStatement.executeUpdate()
在本小节中,我们将首先介绍driver模块的基本使用;接着介绍parser模块是如何使用driver模块的;最后讲解driver模块的实现原理。
driver模块的基本使用
本小节将会介绍MysqlConnector和MysqlQueryExecutor、MysqlUpdateExecutor如何使用。
假设test库下有一张mysql表:userCREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(18) NOT NULL, `password` varchar(15) NOT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;该表中有2条记录:
mysql> select * from t_user; +----+---------------+----------+ | id | name | password | +----+---------------+----------+ | 1 | tianshozhi | xx | | 2 | wangxiaoxiiao | yy | +----+---------------+----------+MysqlConnector
MysqlConnector相当于一个数据链接,其使用方式如下所示:
@Test public void testMysqlConnection(){ MysqlConnector connector = new MysqlConnector(); try { //1 创建数据库连接 connector = new MysqlConnector(); // 设置数据库ip、port connector.setAddress(new InetSocketAddress("127.0.0.1", 3306)); // 设置用户名 connector.setUsername("root"); // 设置密码 connector.setPassword(“your password"); // 设置默认连接到的数据库 connector.setDefaultSchema("test"); // 设置链接字符串,33表示UTF-8 connector.setCharsetNumber((byte) 33); // ======设置网络相关参数=========== // 设置socket超时时间,默认30s,也就是发送一个请求给mysql时,如果30s没响应,则会抛出SocketTimeoutException connector.setSoTimeout(30 * 1000); // 设置发送缓冲区发小,默认16K connector.setSendBufferSize(16 * 1024);// 16K // 设置接受缓冲区大小,默认16K connector.setReceiveBufferSize(16 * 1024);// 16k //调用connect方法建立连接 connector.connect(); //2 ... do something.... }catch (IOException e){ e.printStackTrace(); }finally { try { //关闭链接 connector.disconnect(); } catch (IOException e) { e.printStackTrace(); } } }一个MysqlConnector实例底层只能维护一个数据库链接。除了上面提到的方法,MysqlConnector还提供了reconnect()方法和fork()方法。
reconnect()方法:
reconnect()内部先调用disconnect方法关闭原有连接,然后使用connect方法创建一个新的连接
mysqlConnector.reconnect();fork()方法:
如果希望创建多个连接,可以fork出一个新的MysqlConnector实例,再调用这个新MysqlConnector实例的connect方法建立连接。
MysqlConnector fork = mysqlConnector.fork(); fork.connect();MysqlQueryExecutor
这里我们使用MysqlQueryExecutor查询数据库中的user表中的两条记录,注意canal的driver模块并没有实现jdbcref规范,因此使用起来,与我们熟悉的JDBC编程有一些区别。
案例代码:
@Test public void testQuery() throws IOException { MysqlConnector connector = new MysqlConnector(new InetSocketAddress("127.0.0.1", 3306),"root”,”your password"); try { //1 创建数据库连接 connector.connect(); //2 构建查询执行器,并执行查询 MysqlQueryExecutor executor = new MysqlQueryExecutor(connector); //ResultSetPacket作用类似于ResultSet ResultSetPacket result = executor.query("select * from test.user"); //3 对查询结果进行解析 //FieldPacket中封装的字段的一些源信息,如字段的名称,类型等 List<FieldPacket> fieldDescriptors = result.getFieldDescriptors(); //字段的值使用String表示,jdbc编程中使用的getInt,getBoolean,getDate等方法,实际上都是都是字符串转换得到的 List<String> fieldValues = result.getFieldValues(); //打印字段名称 for (FieldPacket fieldDescriptor : fieldDescriptors) { String fieldName = fieldDescriptor.getName(); System.out.print(fieldName + " "); } //打印字段的值 System.out.println("\n" + fieldValues); } finally { connector.disconnect(); } }控制台输出如下:
id name password [1, tianshozhi, xx, 2, wangxiaoxiiao, yy]可以看出来:
对user表中的字段信息,canal中使用FieldPacket来表示,放于一个List表示。 对于user表中的一行记录,使用另一个List表示,这个List的大小是字段的List大小的整数倍,前者size除以后者就是查询出来的行数。MysqlUpdateExecutor
使用案例
@Test public void testUpdate() { MysqlConnector connector = new MysqlConnector(new InetSocketAddress("127.0.0.1", 3306), "root", "xx"); try { connector.connect(); MysqlUpdateExecutor executor = new MysqlUpdateExecutor(connector); OKPacket okPacket = executor.update("insert into test.user(name,password) values('tianbowen','zzz')"); System.out.println(JSON.toJSONString(okPacket,true)); } catch (IOException e) { e.printStackTrace(); } finally { try { connector.disconnect(); } catch (IOException e) { e.printStackTrace(); } } }如果执行更新操作成功,返回的是一个OkPacket,上面把OkPacket转成JSON,控制台输出如下:
{ "affectedRows":"AQ==", "fieldCount":0, "insertId":"AQ==", "message":"", "serverStatus":2, "warningCount":0 }可以看到这里OkPacke包含的信息比较多。其中比较重要的是:sql操作影响的记录行数affectedRows,以及insert操作返回自动生成的主键insertId。
这里返回的insertId和affectedRows都是字节数组,我们需要将其转换为数字,以insertId为例,其转换方式如下;bytes[] insertId=okPacket.getInsertId(); long autoGeneratedKey = ByteHelper.readLengthCodedBinary(insertId, 0); System.out.println(autoGeneratedKey);parser模块 是如何使用driver模块的?
分析canal是如何使用driver模块的,主要就是看其他模块使用driver模块执行了哪些查询和更新sql。由于canal的作用主要是解析binlog,因此执行的大多都是binlog解析过程中所需要使用的sql语句。
显然parser模块需要依靠driver模块来获取原始的binlog二进制字节流,因此相关sql都在driver模块中。parser模块执行的更新sql
parser模块提供了一个MysqlConnection对driver模块的MysqlConnector进行了封装,在开始dump binlog前,会对当前链接进行一些参数设置,如下图: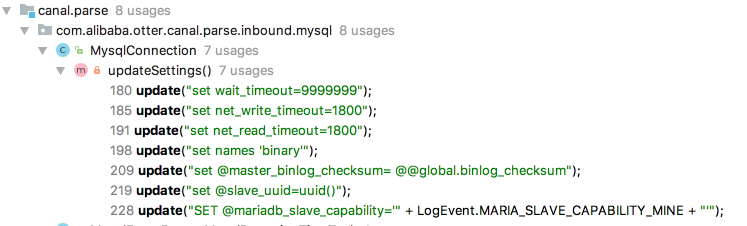
com.alibaba.otter.canal.parse.inbound.mysql.MysqlConnection#updateSettings
其中:
1 set wait_timeout=9999999
2 set net_write_timeout=1800
3 set net_read_timeout=1800
4 set names ‘binary’
设置服务端返回结果时不做编码转化,直接按照数据库的二进制编码进行发送,由客户端自己根据需求进行编码转化set @master_binlog_checksum= @@global.binlog_checksum
mysql5.6针对checksum支持需要设置session变量如果不设置会出现错误:
Slave can not handle replication events with the checksum that master is configured to log但也不能乱设置,需要和mysql server的checksum配置一致,不然RotateLogEvent会出现乱码。’@@global.binlog_checksum’需要去掉单引号,在mysql 5.6.29下导致master退出
5 set @slave_uuid=uuid()
mysql5.6需要设置slave_uuid避免被server kill链接,参考:https://github.com/alibaba/canal/issues/2846 SET @mariadb_slave_capability=’" + LogEvent.MARIA_SLAVE_CAPABILITY_MINE + "’
mariadb针对特殊的类型,需要设置session变量parser模块执行的查询sql
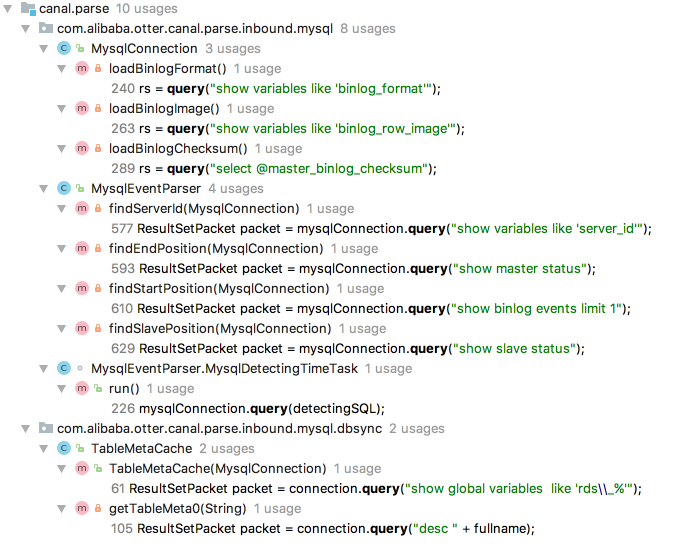
7 show variables like ‘binlog_format’
用于查看binlog格式,值为STATEMENT,MIXED,ROW的一种,如:mysql> show variables like 'binlog_format'; +---------------+-------+ | Variable_name | Value | +---------------+-------+ | binlog_format | ROW | +---------------+-------+8 show variables like ‘binlog_row_image’
-
ROW模式下,即使我们只更新了一条记录的其中某个字段,也会记录每个字段变更前后的值,binlog日志就会变大,带来磁盘IO上的开销,以及网络开销。mysql提供了参数binlog_row_image,来控制是否需要记录每一行的变更,其有3个值:
-
FULL : 记录列的所有修改
-
MINIMAL :只记录修改的列。
-
NOBLOB :如果是text类型或clob字段,不记录 这些日志
如:
mysql> show variables like 'binlog_row_image'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | binlog_row_image | FULL | +------------------+-------+9 select @master_binlog_checksum
mysql 主从复制(replication) 同步可能会出现数据不一致,mysql 5.6 版本中加入了 replication event checksum(主从复制事件校验)功能。默认开启。如果开启,每个binlog后面会多出4个字节,为CRC32校验值。目前cancal支持解析CRC32的值,但不会进行校验。如:
mysql> show variables like 'binlog_checksum'; +-----------------+-------+ | Variable_name | Value | +-----------------+-------+ | binlog_checksum | CRC32 | mysql> select @master_binlog_checksum; +-------------------------+ | @master_binlog_checksum | +-------------------------+ | NULL | +-------------------------+ 1 row in set (0.01 sec)10 show variables like ‘server_id’
mysql主从同步时,每个机器都要设置一个唯一的server_id,canal连接到某个mysql实例之后,会查询这个serverId。11 show master status
mysql binlog是多文件存储,唯一确定一个binlog位置需要通过:binlog file + binlog position。show master status可以获得当前的binlog位置,如:mysql> show master status; +--------------+----------+--------------+------------------+-------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set | +--------------+----------+--------------+------------------+-------------------+ | mysql.000012 | 23479 | | | | +--------------+----------+--------------+------------------+-------------------+12 show binlog events limit 1
查询最早的binlog位置。mysql> show binlog events limit 1; +--------------+-----+-------------+-----------+-------------+---------------------------------------+ | Log_name | Pos | Event_type | Server_id | End_log_pos | Info | +--------------+-----+-------------+-----------+-------------+---------------------------------------+ | mysql.000001 | 4 | Format_desc | 1 | 123 | Server ver: 5.7.18-log, Binlog ver: 4 | +--------------+-----+-------------+-----------+-------------+---------------------------------------+mysql binlog文件默认从mysql.000001开始,前四个字节是魔法字节,是固定的。因此真正的binlog事件总是从第4个字节之后才开始的。
binlog文件可能会清空,官方的mysql版支持设置参数expire_logs_days来控制binlog保存时间,一些分支如percona,支持指定报文binlog文件个数。主要是避免binlog过多导致磁盘空间不足。
13 show slave status
主要用于判断MySQL复制同步状态,这个命令的内容比较多,这里不演示。主要是关注两个线程的状态:-
Slave_IO_Running线程:负责把主库的bin日志(Master_Log)内容,投递到从库的中继日志上(Relay_Log)
-
Slave_SQL_Running线程:负责把中继日志上的语句在从库上执行一遍
以及Seconds_Behind_Master的值,其表示从库落后主库的时间,如果为0则表示没有延迟。
show global variables like 'rds\_%'这个命令没懂,猜测应该是判断是否数据库是否是是否是阿里云上提供的rds。"desc " + fullname查看库表的字段定义,如:mysql> desc test.user; +----------+-------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +----------+-------------+------+-----+---------+----------------+ | id | int(11) | NO | PRI | NULL | auto_increment | | name | varchar(18) | NO | | NULL | | | password | varchar(15) | NO | | NULL | | +----------+-------------+------+-----+---------+----------------+原始的binlog二进制流中,并不包含字段的名称,而canal提供个client订阅的event中包含了字段名称,实际上就是通过这个命令来获得的。parser模块的TableMetaCache类就是用于缓存表字段信息。当表结构变更后,也会跟着自动跟新。
Driver模块实现原理
canal的driver模块实际上就是一个手功编写的一个mysql客户端。要编写这样的一个客户端并不容易,需要参考Mysql client/server通信协议,以下是地址:
https://dev.mysql.com/doc/internals/en/client-server-protocol.html笔者也尝试自己写了一些功能,最终的体会是,要实现一个完整的客户端,太多细节要考虑,没有足够的时间。另外一点,也建议读者可以阅读一下这个通信协议即可,以便对driver模块有更深的理解。建议不要花太多时间。
事实上canal的driver客户端也没有实现完整的通信协议,只是满足了简单的查询和更新功能。不过从binlog解析的角度,这已经足够了。
本文转载自田守枝的Java技术博客,感谢作者的分享
-