canal源码解析系列(4):instance模块
-
系列文章索引:
在上一节server模块源码分析中,我们提到CanalServerWithNetty封装了一层网络请求协议,将请求委派给CanalServerWithEmbedded处理。CanalServerWithEmbedded会根据请求携带的destination参数,选择对应的CanalInstance来真正的处理请求。这正是一步一步抽丝剥茧的过程,在本节中,我们将要分析CanalInstance的源码。
CanalInstance源码概览
CanalInstance相关代码位于canal源码的instance模块中,这个模块又有三个子模块,如下所示:

-
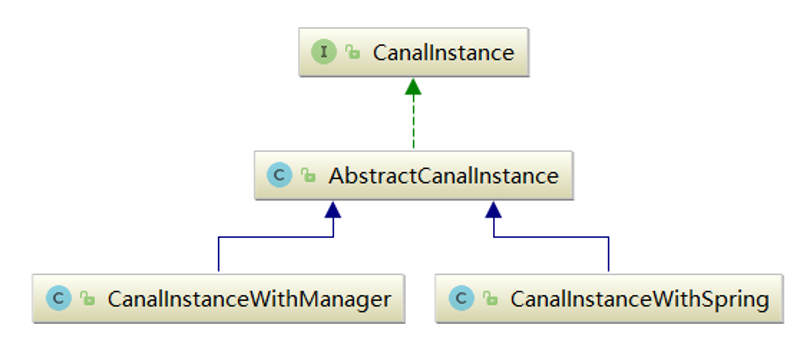
在core模块中,定义了CanalInstance接口,以及其抽象类子类AbstractCanalInstance。
-
在spring模块,提供了基于spring配置方式的CanalInstanceWithSpring实现,即CanalInstance实例的创建,通过spring配置文件来创建。
- 在manager模块中,提供了基于manager配置方式的CanalInstanceWithManager实现,即CanalInstance实例根据远程配置中心的内容来创建。
CanalInstance类图继承关系如下所示:
在本节中,我们主要以spring配置方式为例,对CanalInstance源码进行解析。CanalInstance接口
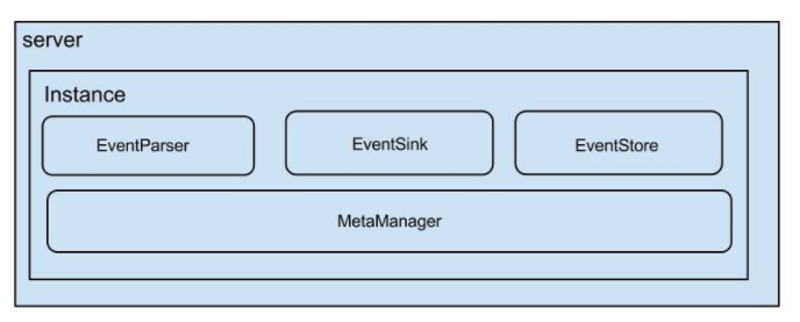
在Canal官方文档中有一张图描述了CanalInstance的4个主要组件,如下:
其中:
event parser:数据源接入,模拟slave协议和master进行交互,协议解析
event sink:parser和store链接器,进行数据过滤,加工,分发的工作
event store:数据存储
meta manager:增量订阅/消费binlog元数据位置存储
在CanalInstance接口中,主要就是定义了获得这几个组成部分的方法:
public interface CanalInstance extends CanalLifeCycle { //这个instance对应的destination String getDestination(); //数据源接入,模拟slave协议和master进行交互,协议解析,位于canal.parse模块中 CanalEventParser getEventParser(); //parser和store链接器,进行数据过滤,加工,分发的工作,位于canal.sink模块中 CanalEventSink getEventSink(); //数据存储,位于canal.store模块中 CanalEventStore getEventStore(); //增量订阅&消费元数据管理器,位于canal.meta模块中 CanalMetaManager getMetaManager(); //告警,位于canal.common块中 CanalAlarmHandler getAlarmHandler(); /** * 客户端发生订阅/取消订阅行为 */ boolean subscribeChange(ClientIdentity identity); }可以看到,instance模块其实是把这几个模块组装在一起,为客户端的binlog订阅请求提供服务。有些模块都有多种实现,不同组合方式,最终确定了一个CanalInstance的工作逻辑。
CanalEventParser接口实现类:
-
MysqlEventParser:伪装成单个mysql实例的slave解析binglog日志
-
GroupEventParser:伪装成多个mysql实例的slave解析binglog日志。内部维护了多个CanalEventParser。主要应用场景是分库分表:比如产品数据拆分了4个库,位于不同的mysql实例上。正常情况下,我们需要配置四个CanalInstance。对应的,业务上要消费数据时,需要启动4个客户端,分别链接4个instance实例。为了方便业务使用,此时我们可以让CanalInstance引用一个GroupEventParser,由GroupEventParser内部维护4个MysqlEventParser去4个不同的mysql实例去拉取binlog,最终合并到一起。此时业务只需要启动1个客户端,链接这个CanalInstance即可.
-
LocalBinlogEventParser:解析本地的mysql binlog。例如将mysql的binlog文件拷贝到canal的机器上进行解析。
CanalEventSink接口实现类:
-
EntryEventSink
-
GroupEventSink:基于归并排序的sink处理
CanalEventStore接口实现类:
- 目前只有MemoryEventStoreWithBuffer,基于内存buffer构建内存memory store
CanalMetaManager:
-
ZooKeeperMetaManager:将元数据存存储到zk中
-
MemoryMetaManager:将元数据存储到内存中
-
MixedMetaManager:组合memory + zookeeper的使用模式
-
PeriodMixedMetaManager:基于定时刷新的策略的mixed实现
-
FileMixedMetaManager:先写内存,然后定时刷新数据到File
关于这些实现的具体细节,我们在相应模块的源码分析时,进行讲解。目前只需要知道,一些组件有多种实现,因此组合工作方式有多种。
AbstractCanalInstance源码分析
AbstractCanalInstance是CanalInstance的抽象子类,定义了相关字段来维护eventParser、eventSink、eventStore、metaManager的引用。public class AbstractCanalInstance extends AbstractCanalLifeCycle implements CanalInstance { private static final Logger logger = LoggerFactory.getLogger(AbstractCanalInstance.class); protected Long canalId; // 和manager交互唯一标示 protected String destination; // 队列名字 protected CanalEventStore<Event> eventStore; // 有序队列 protected CanalEventParser eventParser; // 解析对应的数据信息 protected CanalEventSink<List<CanalEntry.Entry>> eventSink; // 链接parse和store的桥接器 protected CanalMetaManager metaManager; // 消费信息管理器 protected CanalAlarmHandler alarmHandler; // alarm报警机制 //... }需要注意的是,在AbstractCanalInstance中,并没有提供方法来初始化这些字段。可以看到,这些字段都是protected的,子类可以直接访问,显然这些字段都是在AbstractCanalInstance的子类中进行赋值的。
AbstractCanalInstance不关心这些字段的具体实现,只是从接口层面进行调用。对于其子类而言,只需要给相应的字段赋值即可。在稍后我们将要讲解的CanalInstanceWithSpring中,你将会发现其仅仅给eventParser、eventSink、eventStore、metaManager几个字段赋值,其他什么工作都没干。 因此,对于instance模块而言,其核心工作逻辑都是在AbstractCanalInstance中实现的。start方法和stop方法:
start方法:
在AbstractCanalInstance的start方法中,主要就是启动各个模块。启动顺序为:metaManager—>eventStore—>eventSink—>eventParser。源码如下所示:
com.alibaba.otter.canal.instance.core.AbstractCanalInstance#start
public void start() { super.start(); if (!metaManager.isStart()) { metaManager.start(); } if (!alarmHandler.isStart()) { alarmHandler.start(); } if (!eventStore.isStart()) { eventStore.start(); } if (!eventSink.isStart()) { eventSink.start(); } if (!eventParser.isStart()) { beforeStartEventParser(eventParser);//启动前执行一些操作 eventParser.start(); afterStartEventParser(eventParser);//启动后执行一些操作 } logger.info("start successful...."); }要理解为什么按照这个顺序启动很简单。官方关于instance模块构成的图中,把metaManager放在最下面,说明其是最基础的部分,因此应该最先启动。
而eventParser依赖于eventSink,需要把自己解析的binlog交给其加工过滤,而eventSink又要把处理后的数据交给eventStore进行存储。因此依赖关系如下:eventStore—>eventSink—>eventParser ,启动的时候也要按照这个顺序启动。stop方法:
在停止的时候,实际上就是停止内部的各个模块,模块停止的顺序与start方法刚好相反
com.alibaba.otter.canal.instance.core.AbstractCanalInstance#stop
@Override public void stop() { super.stop(); logger.info("stop CannalInstance for {}-{} ", new Object[] { canalId, destination }); if (eventParser.isStart()) { beforeStopEventParser(eventParser);//停止前执行一些操作 eventParser.stop(); afterStopEventParser(eventParser);//停止后执行一些操作 } if (eventSink.isStart()) { eventSink.stop(); } if (eventStore.isStart()) { eventStore.stop(); } if (metaManager.isStart()) { metaManager.stop(); } if (alarmHandler.isStart()) { alarmHandler.stop(); } logger.info("stop successful...."); }start和stop方法对eventParser的特殊处理
在AbstractCanalInstance的start和stop方法,对于eventParser这个组件的启动和停止,都有一些特殊处理,以下是相关代码片段:--start方法 beforeStartEventParser(eventParser);//启动前执行一些操作 eventParser.start(); afterStartEventParser(eventParser);//启动后执行一些操作 --stop方法 beforeStopEventParser(eventParser);//停止前执行一些操作 eventParser.stop(); afterStopEventParser(eventParser);//停止后执行一些操作这与eventParser的自身构成有关系。canal官方文档DevGuide中,关于eventParser有以下描述: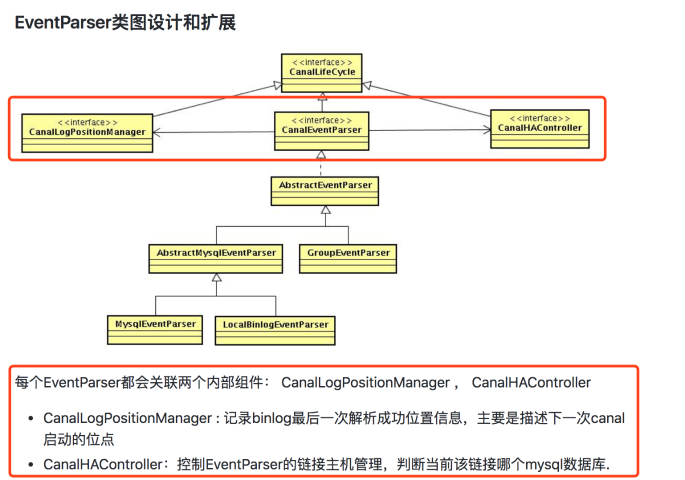
因此,eventParser在启动之前,需要先启动**CanalLogPositionManager和CanalHAController**。
关于CanalLogPositionManager,做一点补充说明。 mysql在主从同步过程中,要求slave自己维护binlog的消费进度信息。canal伪装成slave,因此也要维护这样的信息。 事实上,如果读者自己搭建过mysql主从复制的话,在slave机器的data目录下,都会有一个master.info文件,这个文件的作用就是存储主库的消费binlog解析进度信息。beforeStartEventParser方法
beforeStartEventParser方法的作用是eventParser前做的一些特殊处理。首先会判断eventParser的类型是否是GroupEventParser,在前面我已经介绍过,这是为了处理分库分表的情况。如果是,循环其包含的所有CanalEventParser,依次调用startEventParserInternal方法;否则直接调用com.alibaba.otter.canal.instance.core.AbstractCanalInstance#beforeStartEventParser
protected void beforeStartEventParser(CanalEventParser eventParser) { //1、判断eventParser的类型是否是GroupEventParser boolean isGroup = (eventParser instanceof GroupEventParser); //2、如果是GroupEventParser,则循环启动其内部包含的每一个CanalEventParser,依次调用startEventParserInternal方法 if (isGroup) { // 处理group的模式 List<CanalEventParser> eventParsers = ((GroupEventParser) eventParser).getEventParsers(); for (CanalEventParser singleEventParser : eventParsers) {// 需要遍历启动 startEventParserInternal(singleEventParser, true); } //如果不是,说明是一个普通的CanalEventParser,直接调用startEventParserInternal方法 } else { startEventParserInternal(eventParser, false); } }从上面的分析中,可以看出,针对单个CanalEventParser,都是通过调用startEventParserInternal来启动的,其内部会启动CanalLogPositionManager和CanalHAController。
com.alibaba.otter.canal.instance.core.AbstractCanalInstance#startEventParserInternal
/** * 初始化单个eventParser,不需要考虑group */ protected void startEventParserInternal(CanalEventParser eventParser, boolean isGroup) { // 1 、启动CanalLogPositionManager if (eventParser instanceof AbstractEventParser) { AbstractEventParser abstractEventParser = (AbstractEventParser) eventParser; CanalLogPositionManager logPositionManager = abstractEventParser.getLogPositionManager(); if (!logPositionManager.isStart()) { logPositionManager.start(); } } // 2 、启动CanalHAController if (eventParser instanceof MysqlEventParser) { MysqlEventParser mysqlEventParser = (MysqlEventParser) eventParser; CanalHAController haController = mysqlEventParser.getHaController(); if (haController instanceof HeartBeatHAController) { ((HeartBeatHAController) haController).setCanalHASwitchable(mysqlEventParser); } if (!haController.isStart()) { haController.start(); } } }关于CanalLogPositionManager和CanalHAController的详细源码,我们将会在分析parser模块的时候进行介绍
afterStartEventParser方法
在eventParser启动后,会调用afterStartEventParser方法。这个方法内部主要是通过metaManager读取一下历史订阅过这个CanalInstance的客户端信息,然后更新一下filter。com.alibaba.otter.canal.instance.core.AbstractCanalInstance#afterStartEventParser
protected void afterStartEventParser(CanalEventParser eventParser) { // 读取一下历史订阅的client信息 List<ClientIdentity> clientIdentitys = metaManager.listAllSubscribeInfo(destination); for (ClientIdentity clientIdentity : clientIdentitys) { //更新filter subscribeChange(clientIdentity); } }subscribeChange 方法
subscribeChange方法,主要是更新一下eventParser中的filter。@Override public boolean subscribeChange(ClientIdentity identity) { if (StringUtils.isNotEmpty(identity.getFilter())) {//如果设置了filter logger.info("subscribe filter change to " + identity.getFilter()); AviaterRegexFilter aviaterFilter = new AviaterRegexFilter(identity.getFilter()); boolean isGroup = (eventParser instanceof GroupEventParser); if (isGroup) { // 处理group的模式 List<CanalEventParser> eventParsers = ((GroupEventParser) eventParser).getEventParsers(); for (CanalEventParser singleEventParser : eventParsers) {// 需要遍历启动 ((AbstractEventParser) singleEventParser).setEventFilter(aviaterFilter); } } else { ((AbstractEventParser) eventParser).setEventFilter(aviaterFilter); } } // filter的处理规则 // a. parser处理数据过滤处理 // b. sink处理数据的路由&分发,一份parse数据经过sink后可以分发为多份,每份的数据可以根据自己的过滤规则不同而有不同的数据 // 后续内存版的一对多分发,可以考虑 return true; }关于filter,进行一下补充说明,filter规定了需要订阅哪些库,哪些表。在服务端和客户端都可以设置,客户端的配置会覆盖服务端的配置。
服务端配置:主要是配置instance.properties中的canal.instance.filter.regex配置项,官网文档关于这个配置项有以下介绍

客户端配置
客户端在订阅时,调用CanalConnector接口中定义的带有filter参数的subscribe方法重载形式
/** * 客户端订阅,重复订阅时会更新对应的filter信息 * * <pre> * 说明: * a. 如果本次订阅中filter信息为空,则直接使用canal server服务端配置的filter信息 * b. 如果本次订阅中filter信息不为空,目前会直接替换canal server服务端配置的filter信息,以本次提交的为准 * </pre> */ void subscribe(String filter) throws CanalClientException;至此,针对start eventParser前后的特殊处理步骤的两个方法:beforeStartEventParser和afterStartEventParser我们已经分析完成。
对于stop eventParser前后做的特殊处理涉及的beforeStopEventParser和afterStopEventParser方法,这里不再赘述。AbstractCanalInstance总结
AbstractCanalInstance源码到目前我们已经分析完成,无非就是在start和stop时,按照一定的顺序启动或停止event store、event sink、event parser、meta manager这几个组件,期间对于event parser的启动和停止做了特殊处理,并没有提供订阅binlog的相关方法。那么如何来订阅binglog数据呢?答案是直接操作器内部组件。 AbstractCanalInstance通过相关get方法直接返回了其内部的组件:@Override public CanalEventParser getEventParser() {return eventParser;} @Override public CanalEventSink getEventSink() {return eventSink;} @Override public CanalEventStore getEventStore() {return eventStore;} @Override public CanalMetaManager getMetaManager() {return metaManager;}在上一节server模块源码分析中,CanalServerWithEmbedded就是直接通过CanalInstance的内部组件,进行操作的。我们再次回顾一下getWithoutAck方法,进行验证:com.alibaba.otter.canal.server.embedded.CanalServerWithEmbedded#getWithoutAck
public Message getWithoutAck(ClientIdentity clientIdentity, int batchSize, Long timeout, TimeUnit unit) throws CanalServerException { checkStart(clientIdentity.getDestination()); checkSubscribe(clientIdentity); CanalInstance canalInstance = canalInstances.get(clientIdentity.getDestination()); synchronized (canalInstance) { //通过canalInstance.getMetaManager() 获取到流式数据中的最后一批获取的位置 PositionRange<LogPosition> positionRanges = canalInstance.getMetaManager().getLastestBatch(clientIdentity); Events<Event> events = null; if (positionRanges != null) { //通过canalInstance.getEventStore()获得binlog事件 events = getEvents(canalInstance.getEventStore(), positionRanges.getStart(), batchSize, timeout, unit); } else {// ack后第一次获取,通过canalInstance.getMetaManager()获得开始位置 Position start = canalInstance.getMetaManager().getCursor(clientIdentity); if (start == null) { // 第一次,还没有过ack记录,通过canalInstance.getEventStore()当前store中的第一条 start = canalInstance.getEventStore().getFirstPosition(); } //通过canalInstance.getEventStore()获得binlog事件 events = getEvents(canalInstance.getEventStore(), start, batchSize, timeout, unit); } if (CollectionUtils.isEmpty(events.getEvents())) { logger.debug("getWithoutAck successfully, clientId:{} batchSize:{} but result is null", new Object[] { clientIdentity.getClientId(), batchSize }); return new Message(-1, new ArrayList<Entry>()); // 返回空包,避免生成batchId,浪费性能 } else { // 通过canalInstance.getMetaManager()记录流式信息 Long batchId = canalInstance.getMetaManager().addBatch(clientIdentity, events.getPositionRange()); List<Entry> entrys = Lists.transform(events.getEvents(), new Function<Event, Entry>() { public Entry apply(Event input) { return input.getEntry(); } }); ... return new Message(batchId, entrys); } } }可以看到AbstractCanalInstance除了负责启动和停止其内部组件,就没有其他工作了。真正获取binlog信息,以及相关元数据维护的逻辑,都是在CanalServerWithEmbedded中完成的。 事实上,从设计的角度来说,笔者认为既然这些模块是CanalInstance的内部组件,那么相关操作也应该封装在CanalInstance的实现类中,对外部屏蔽,不应该把这些逻辑放到CanalServerWithEmbedded中实现。 最后,AbstractCanalInstance中并没有metaManager、eventSink、eventPaser,eventStore这几个组件。这几个组件的实例化是在AbstractCanalInstance的子类中实现的。AbstractCanalInstance有2个子类:CanalInstanceWithSpring和CanalInstanceWithManager。我们将以CanalInstanceWithSpring为例进行说明如何给这几个组件赋值。CanalInstanceWithSpring
CanalInstanceWithSpring是AbstractCanalInstance的子类,提供了一些set方法为instance的组成模块赋值,如下所示:public class CanalInstanceWithSpring extends AbstractCanalInstance { private static final Logger logger = LoggerFactory.getLogger(CanalInstanceWithSpring.class); public void start() { logger.info("start CannalInstance for {}-{} ", new Object[] { 1, destination }); super.start(); } // ======== setter ======== public void setDestination(String destination) { this.destination = destination; } public void setEventParser(CanalEventParser eventParser) { this.eventParser = eventParser; } public void setEventSink(CanalEventSink<List<CanalEntry.Entry>> eventSink) { this.eventSink = eventSink; } public void setEventStore(CanalEventStore<Event> eventStore) { this.eventStore = eventStore; } public void setMetaManager(CanalMetaManager metaManager) { this.metaManager = metaManager; } public void setAlarmHandler(CanalAlarmHandler alarmHandler) { this.alarmHandler = alarmHandler; } }当我们配置加载方式为spring时,创建的CanalInstance实例类型都是CanalInstanceWithSpring。canal将会寻找本地的spring配置文件来创建instance实例。canal默认提供了一下几种spring配置文件:
-
spring/memory-instance.xml
-
spring/file-instance.xml
-
spring/default-instance.xml
-
spring/group-instance.xml
在这4个配置文件中,我们无一例外的都可以看到以下bean配置:
<!--注意class属性都是CanalInstanceWithSpring--> <bean id="instance" class="com.alibaba.otter.canal.instance.spring.CanalInstanceWithSpring"> <property name="destination" value="${canal.instance.destination}" /> <property name="eventParser"> <ref local="eventParser" /> </property> <property name="eventSink"> <ref local="eventSink" /> </property> <property name="eventStore"> <ref local="eventStore" /> </property> <property name="metaManager"> <ref local="metaManager" /> </property> <property name="alarmHandler"> <ref local="alarmHandler" /> </property> </bean>这四个配置文件创建的bean实例都是CanalInstanceWithSpring,但是工作方式却是不同的,因为在不同的配置文件中,eventParser、eventSink、eventStore、metaManager这几个属性引用的具体实现不同。
memory-instance.xml
所有的组件(parser , sink , store)都选择了内存版模式,记录位点的都选择了memory模式,重启后又会回到初始位点进行解析
特点:速度最快,依赖最少(不需要zookeeper)
场景:一般应用在quickstart,或者是出现问题后,进行数据分析的场景,不应该将其应用于生产环境
<bean id="metaManager" class="com.alibaba.otter.canal.meta.MemoryMetaManager" /> <bean id="eventStore" class="com.alibaba.otter.canal.store.memory.MemoryEventStoreWithBuffer"> ... </bean> <bean id="eventSink" class="com.alibaba.otter.canal.sink.entry.EntryEventSink"> <property name="eventStore" ref="eventStore" /> </bean> <bean id="eventParser" class="com.alibaba.otter.canal.parse.inbound.mysql.MysqlEventParser”> ... </bean>file-instance.xml
所有的组件(parser , sink , store)都选择了基于file持久化模式,注意,不支持HA机制.
特点:支持单机持久化
场景:生产环境,无HA需求,简单可用.
<bean id="metaManager" class="com.alibaba.otter.canal.meta.FileMixedMetaManager"> <property name="dataDir" value="${canal.file.data.dir:../conf}" /> <property name="period" value="${canal.file.flush.period:1000}" /> </bean> <bean id="eventStore" class="com.alibaba.otter.canal.store.memory.MemoryEventStoreWithBuffer"> ... </bean> <bean id="eventSink" class="com.alibaba.otter.canal.sink.entry.EntryEventSink"> <property name="eventStore" ref="eventStore" /> </bean> <bean id="eventParser" class="com.alibaba.otter.canal.parse.inbound.mysql.MysqlEventParser”> ... </bean>在这里,有一点需要注意,目前开源版本的eventStore只有基于内存模式的实现,因此官方文档上说store也是基于file持久化的描述是错误的。default-instance.xml:
所有的组件(parser , sink , store)都选择了持久化模式,目前持久化的方式主要是写入zookeeper,保证数据集群共享.
特点:支持HA
场景:生产环境,集群化部署.
<!--注意,由于default-instance.xml支持同ZK来进行HA保障,所以多了此项配置--> <bean id="zkClientx" class="org.springframework.beans.factory.config.MethodInvokingFactoryBean" > <property name="targetClass" value="com.alibaba.otter.canal.common.zookeeper.ZkClientx" /> <property name="targetMethod" value="getZkClient" /> <property name="arguments"> <list> <value>${canal.zkServers:127.0.0.1:2181}</value> </list> </property> </bean> <bean id="metaManager" class="com.alibaba.otter.canal.meta.PeriodMixedMetaManager"> <property name="zooKeeperMetaManager"> <bean class="com.alibaba.otter.canal.meta.ZooKeeperMetaManager"> <property name="zkClientx" ref="zkClientx" /> </bean> </property> <property name="period" value="${canal.zookeeper.flush.period:1000}" /> </bean> <bean id="eventStore" class="com.alibaba.otter.canal.store.memory.MemoryEventStoreWithBuffer"> ... </bean> <bean id="eventSink" class="com.alibaba.otter.canal.sink.entry.EntryEventSink"> <property name="eventStore" ref="eventStore" /> </bean> <bean id="eventParser" class="com.alibaba.otter.canal.parse.inbound.mysql.MysqlEventParser”> ... </bean>group-instance.xml:
主要针对需要进行多库合并时,可以将多个物理instance合并为一个逻辑instance,提供客户端访问。
场景:分库业务。 比如产品数据拆分了4个库,每个库会有一个instance,如果不用group,业务上要消费数据时,需要启动4个客户端,分别链接4个instance实例。使用group后,可以在canal server上合并为一个逻辑instance,只需要启动1个客户端,链接这个逻辑instance即可.
<bean id="metaManager" class="com.alibaba.otter.canal.meta.MemoryMetaManager" /> <bean id="eventStore" class="com.alibaba.otter.canal.store.memory.MemoryEventStoreWithBuffer"> ... </bean> <bean id="eventSink" class="com.alibaba.otter.canal.sink.entry.EntryEventSink"> <property name="eventStore" ref="eventStore" /> </bean> <bean id="eventParser" class="com.alibaba.otter.canal.parse.inbound.group.GroupEventParser"> <property name="eventParsers"> <list> <ref bean="eventParser1" /> <ref bean="eventParser2" /> </list> </property> </bean>细心的读者会发现,这几个不同的spring配置文件中,最主要的就是metaManager 和eventParser 这两个配置有所不同,eventStore 、和eventSink 定义都是相同的。这是因为:
eventStore:目前的开源版本中eventStore只有一种基于内存的实现,所以配置都相同
eventSink:其作用是eventParser和eventStore的链接器,进行数据过滤,加工,分发的工作。不涉及存储,也就没有必要针对内存、file、或者zk进行区分。
最后,上面只是列出了这几个模块spring配置文件不同定义,特别的针对metaManager和eventParser具体属性配置都没有介绍,我们将会在相应模块的源码分析中进行讲解。本文转载自田守枝的Java技术博客,感谢作者的分享
-